AMD ZEN x86 arhitektura
Datum objave 24.08.2016 - Krešimir Matanović
AMD ZEN x86 arhitektura

AMD je na ovogodišnjoj HotChips konferenciji u Cupertinu detaljnije predstavio svoju novu ZEN x86 arhitekturu koja će zaživjeti početkom 2017. godine najprije u Summit Ridge desktop procesorima, a nakon toga i u ostatku ponude. ZEN je potpuno nova arhitektura na kojoj je AMD radio posljednje četiri godine. Puno je toga novoga, pa je AMD-ov Senior Fellow Mike Clark održao trideset minutno predstavljanje i uvod u ZEN x86 arhitekturu.
Kao što dobro znamo, AMD je sa x86 arhitekturom i performansama dosta zaostao iza glavnog konkurenta Intela i Bulldozer arhitektura te njene novije varijacije nikako nisu uspijevale uloviti korak u zadnjih šest godina. Shvativši kako ih ta arhitektura neče daleko odvesti, AMD je prije četiri godine započeo s radom na potpuno novoj arhitekturi koju su nazvali Zen. Shvatili su kako moraju podići IPC performanse za kako bi ulovili korak s konkurencijom, ali i uvesti simultani višenitni rad. Nakon godina razvoja nova je arhitektura spremna za tržište, a po njihovim je riječima Zen nizom poboljšanja uspio podići IPC za 40% u odnosu na prethodnu generaciju, te ostati u istom TDP-u.

Zen je potpuno nova arhitektura napravljena na čistom komadu papira, u kojoj su neki novi arhitekturalni detalji ali je naravno prenesen i dio starijih značajki kao što su Stack engine, Branch funkcija, x86 Decoder i slično. Kako bi postigli 40% povećanja IPC (instructions per clock) performansi donijeli su neke nove značajke poput SMT-a (dva threada po jezgri), poboljšali su predviđanje grananja instrukcija tj. kondicionalne skokove (dva grananja po BTB unosu), dodali su veliku operacijsku priručnu memoriju, proširili otpremanje mikro operacija sa 4 na 6, povećali instrukcijske schedulere (za integer sa 48 na 84, za floating point sa 60 na 96), povećali umirovljenje operacija sa 4 na 8 istovremenih, tu je Quad Issue floating point jedinica, Queue za umirovljenje je povećan sa 128 na 192, Queue za punjenje je povećan sa 44 na 72, a Queue za spremanje sa 32 na 44.
Sistem priručne memorije je poboljšan s uvođenjem Write back L1 keš memorije (naspram write through), ubrzane su L2 i L3 keš memorije, smanjeni je vrijeme punjenja FPU-a sa devet na sedam ciklusa, poboljšan je prefetcher za L1 i L2 memoriju kojima je i gotovo pa poduplana propusnost, a L3 memoriji je propusnost povećana za gotovo pet puta.
40% povećanja performansi je lako dobiti 40 postotnim povećanjem snage i potrošnje, no AMD-ovi su inženjeri htjeli ostati u istom TDP-u pa su uveli agresivniji “clock gating” s višestrukim regijama u logici, smanjenju potrošnje je doprinijelo u i uvođenje write back L1 memorije, zatim velike operacijske priručne memorije (skraćuje pipeline i eliminira potrebu za high-power decode jedinicom), poboljšanjima u stack engine-u, Move elimination funkcije (mijenjanje pointera u registrima umjesto fizičkog seljenja podataka), a koristili su i metodologije naučene kroz razvoj Bulldozer arhitekture za smanjenje potrošnje.
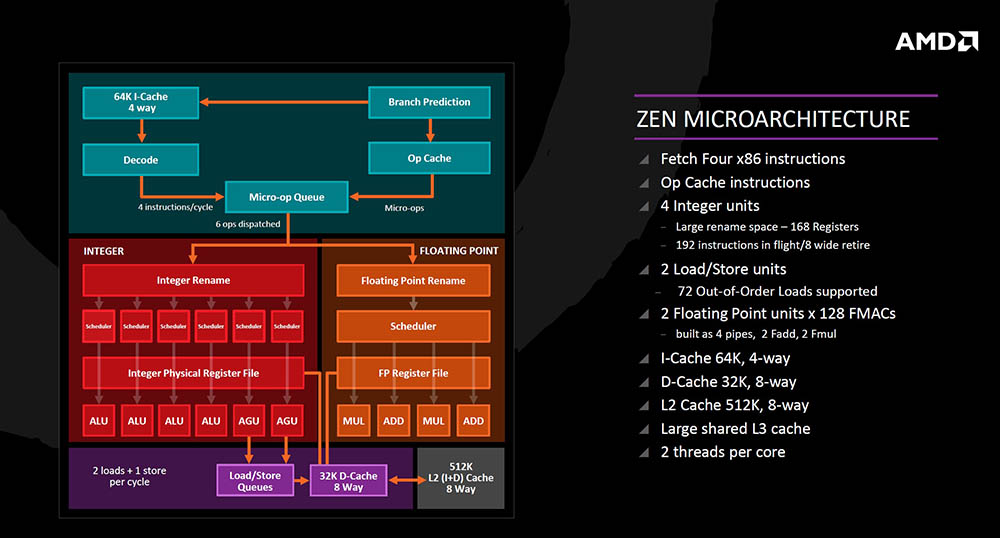
Zen arhitektura funkcionira na način da iz Branch Prediction jedinice postoje dva puta za x86 instrukciju – tradicionalnim putem u instrukcijski keš nakon čega ide u dekoder i micro-op queue, ili novim putem u veliki operacijski keš i micro-op queue, čime se skraćuje put i ubrzava izvršavanje. Iz micro-op queue-a je moguće odaslati šest operacija po ciklusu u izvršnu jedinicu odnosno integer (šest pipelinea) i floating point (četiri pipelinea) koji su u potpunosti u odvojenim pipeline-ima sa svojim jedinicama (scheduleri, registri te ALU (aritmetičko logička jedinica), AGU (generator adresa), MUL (množenje) i ADD (zbrajanje) jedinice). AGU puni 32K 8-way podatkovni keš (dva load i jedan store po ciklusu) nakon čega dolazi 512K L2 8-way keš memorija i velika dijeljena L3 keš memorija. U osnovi to izgleda tako, a malo dubljom analizom se bavimo pregledom naredbi dohvata, dekodiranja, izvršavanja, spremanja i dohvata iz keš memorije itd. na sljedećim slajdovima.
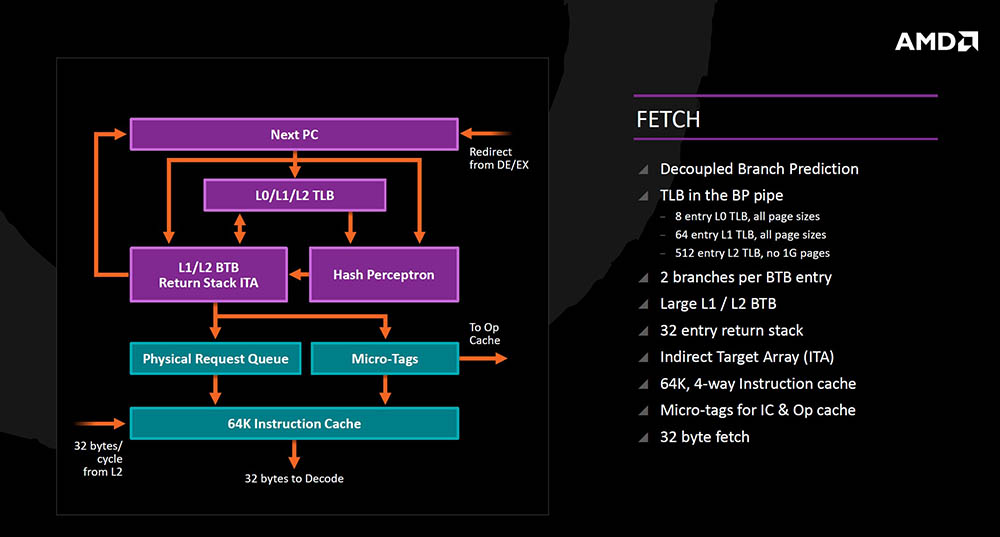
Kod dohvata instrukcija je predviđanje grananja odvojeno od pristupa keš memoriji, a TLB (translation lookaside buffer) je sada smješten u pipeline za predviđanje grananja čime je ubrzan prefetch a podijeljen je i na tri dijela (8 entry, 64 entry i 512 entry), a BTB (branch target buffer) sprema dva grananja po unosu što eliminira potrebu dvostrukog čitanja BTB-a, a pri čemu pomažu i veće L1 i L2 BTB memorije. Dodan je i 32 entry povratni stack (predviđanje povratnih instrukcija), te Indirect Target Array. Kod pristupa keš memoriji su dodani Micro Tagovi koji određuju da li će instrukcija završiti u Operacijskoj keš memoriji za brže izvršenje ili pak u 64KB 4-way instrukcijskoj keš memoriji koja dekoderu može poslati 32 bajta podataka po ciklusu.
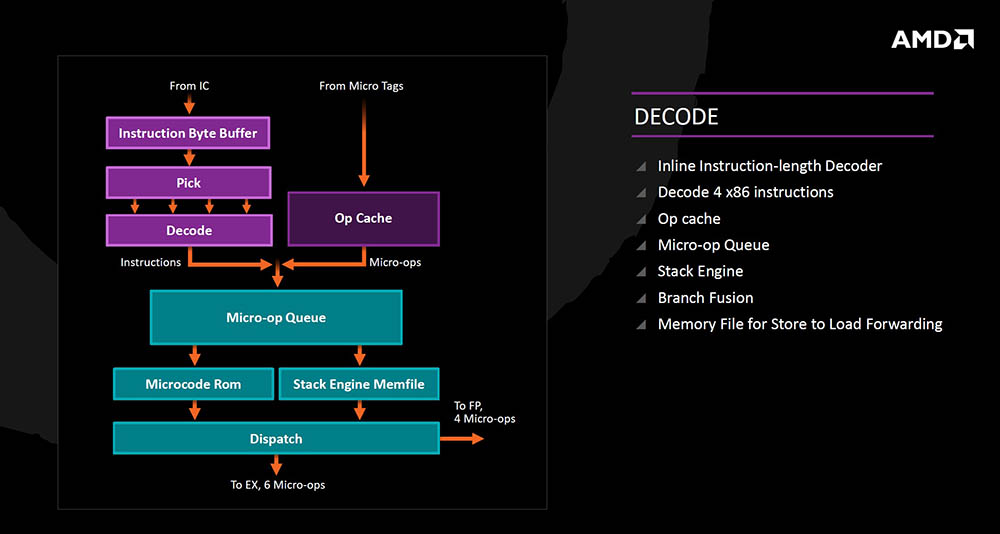
Nadalje instrukcije iz Operacijske keš memorije (brži scenarij) ili pak instrukcijske keš memorije (sporiji scenarij) idu u Micro-op queue pa prema dispatchu i izvršnoj jedinici. Ovdje imamo Stack Engine i Branch Fusion funkcije, kao i memorijski fajl za Store to Load Forwarding.
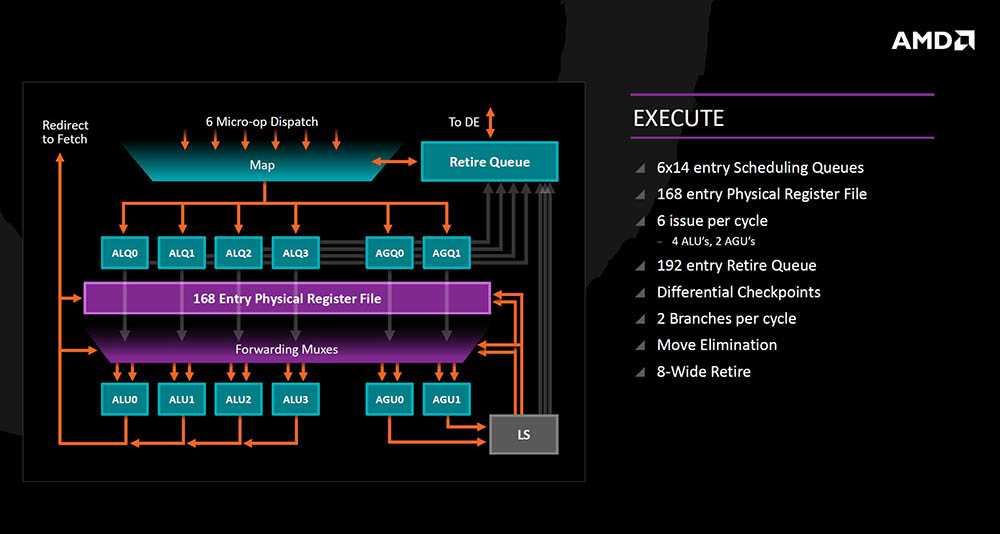
Izvršna jedinica (integer) prima šest micro-operacija u Mapper koje se prate i mogu otići u Retire Queue (in-order umirovljenje), ili u out-of-order izvršnu jedinicu koja se sastoji od četiri ALU jedinice i četiri AGU jedinice (obje 14 entry). Zbog SMT-a se mogu obraditi dvije “grane” po ciklusu, ali naravno i samo jedna.
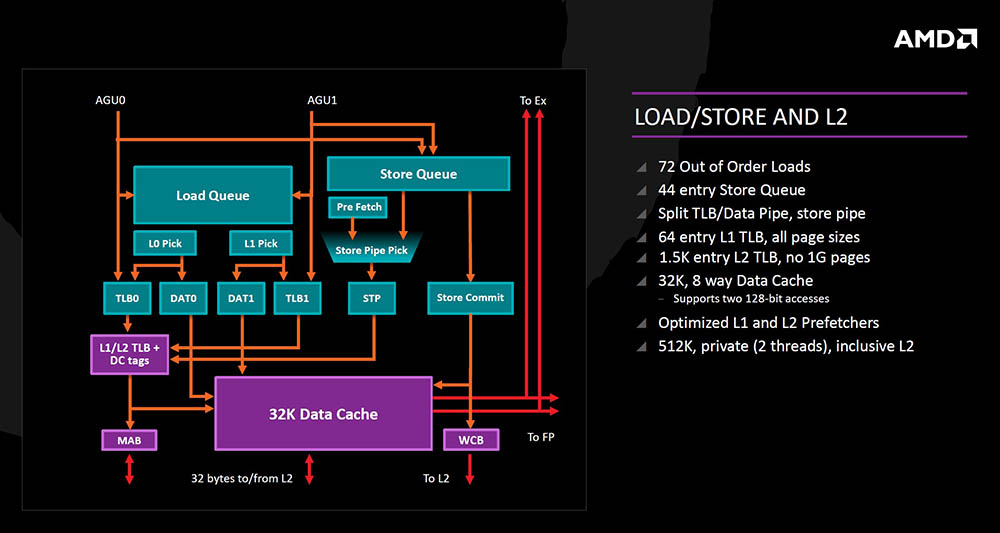
Load/Store jedinica prima 72 Out of Order unosa, ima Store Queue od 44 entry-a, odvojene TLB/Data cjevovode (omogućen pristup podacima dok su u keš memoriji). L1/L2 keš memorija je optimizirana i ubrzana, a i prefetcher-i su optimizirani.
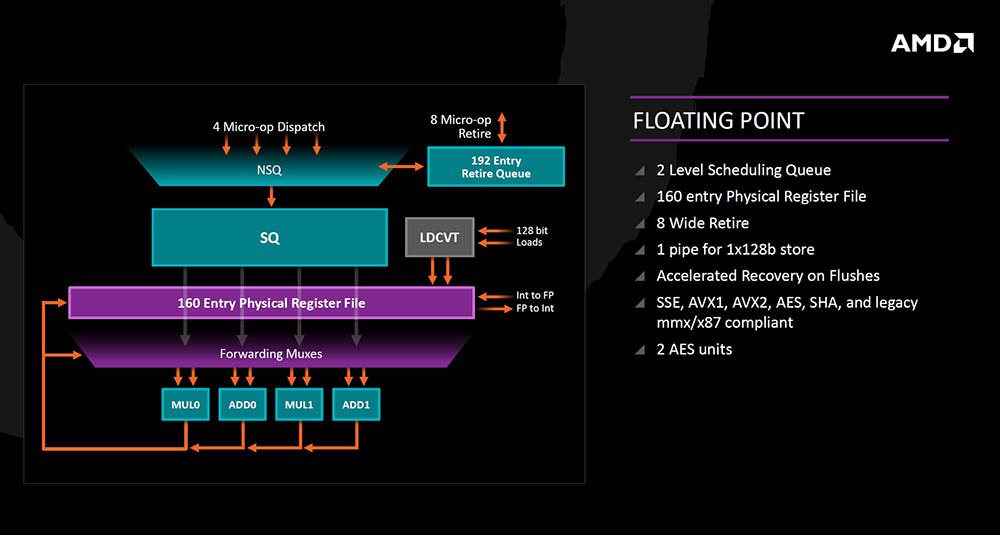
Na Floating point strani se o obrađuju četiri mikro operacije po ciklusu koje ulaze u scheduling queue koji je podijeljen na dvije razine ili pak odlaze u 192 entry retire queue. Fizički registar je 160 entry, podržane su sve tradicionalne setove instrukcija a tu su i dvije AES jedinice za enkripciju.
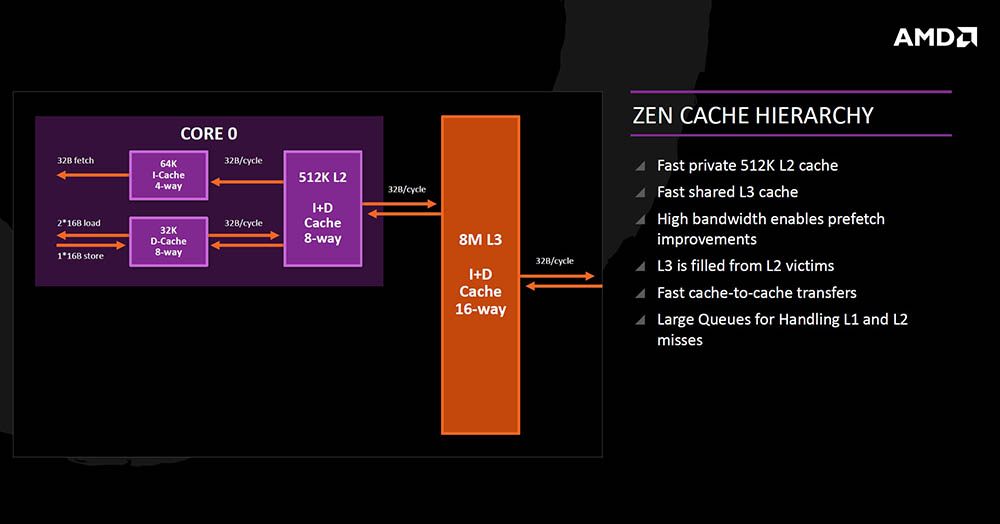
Hijerarhija keš memorije je takva da svaka jezgra ime 64KB 4-way instrukcijske Level 1 memorije, zatim 32KB 8-way podatkovne L1 memorije, te 512KB Level 2 instrukcijske i podatkovne 16-way memorije. Po jednom je ciklusu moguće prenijeti 32 bajta podataka iz keša u keš.
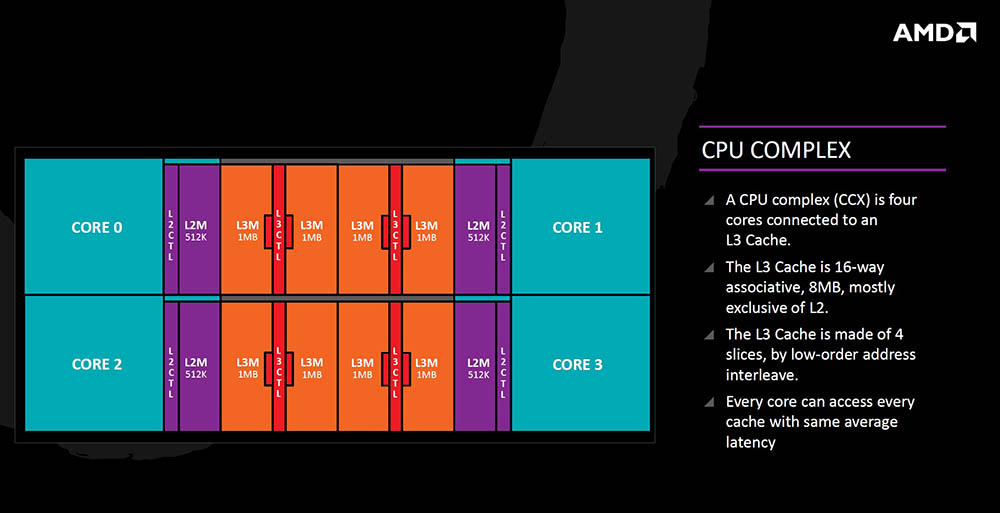
Iz CPU perspektive (CCX) to izgleda ovako – četiri su x86 jezgre spojene na 8MB L3 memorije koja je podijeljena na dijelove od po 1MB (slices) i dijele ju međusobno. Svaka jezgra ima pristup svakom dijelu memorije u nekom prosječnom vremenu pristupa (latenciji), s jasno bržim pristupom onom dijelu koji joj je bliži. Za procesore koji će imati 8 jezgri to znači i kako će biti po 16 MB L3 memorije na jednom fizičkom procesoru. Komunikacija između dva CCX-a na osam jezgrenim procesorima će se odvijati putem veze koju AMD još za sada samo naziva “data fabric”, a koja će biti veza i s memorijom (neće biti HyperTransport).
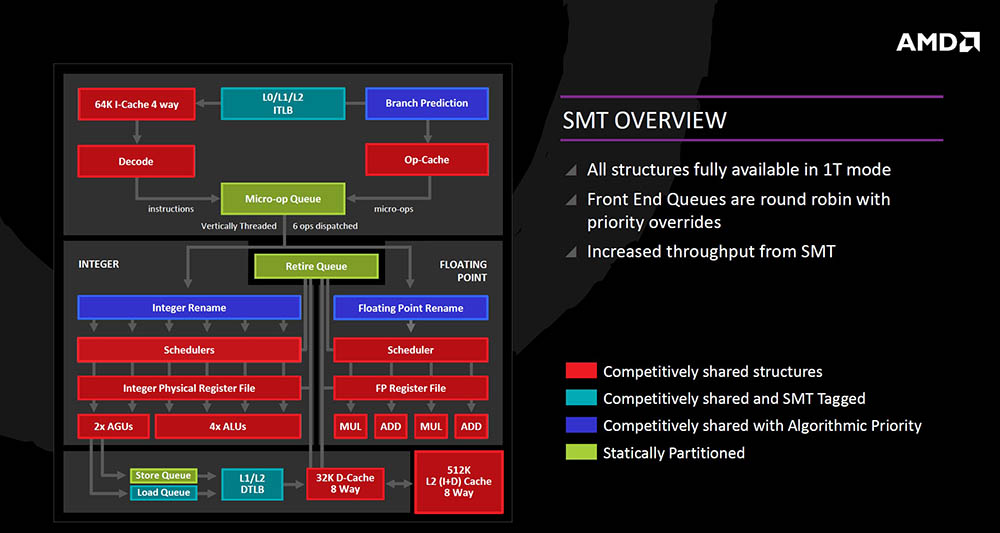
SMT (simultaneous multi threading) je zamišljen tako da kod jednog threada (1T), arhitektura bude maksimalno učinkovita, dok kod 2T moda strukture budu kompetitivno dijeljene, u smislu da program koji zahtjeva veće resurse te resurse i dobije. Neke strukture su uz to što su kompetitivno dijeljenje ujedno i označene za pojedini thread, dok su druge dijeljenje s po algoritamskom prioritetu (prioritiziranje thread-a), a neke su i statički particionirane za jedan thread (zbog smanjenja kompleksnosti izvedbe).
Uz sve standardne instrukcije koje procesor podržava i koje su jednake kao i kod konkurencije (ADX, RDSEED, SMAP, SHA1/SHA256, CLFUSHOPT, XSAVEC/XSAVES/XRSTORS), te ISA instrukcije, tu su i dvije jedinstvene za ZEN – CLZERO (Clear Cache Line) i PTE Coalescing (kombiniranje 4K stranica u 32K stranicu).
Na kraju je svog izlaganja Mike Clark rezimirao kako Zen donosi potpuno novi dizajn high-performance jezgre, novi high-bandwidth – low latency cache sistem, podršku za SMT i energetski efikasan FinFET dizajn (proizvodni proces) koji će omogućiti skaliranje od Enterprise pa do klijentskih rješenja i proizvoda. Uz to, napomenuo je i kako je ovo samo početak i kako se već priprema Zen+ arhitektura, tj. njena poboljšanja i nadogradnje.
Sada kada znamo više o Zen-u, jedva čekamo i nove procesore u 2017. godini za potvrdu tih 40% povećanja IPC-a, a i krajnje je vrijeme da se AMD vrati u koliko toliko kompetitivnu utrku s Intelom.
Forum
Objavljeno prije 3 sata
Sam svoj majstor - razni radovi po kući/stanuObjavljeno prije 5 sati
AutomobiliObjavljeno prije 5 sati
Što trenutno igrate?Objavljeno prije 5 sati
PutovanjaObjavljeno prije 5 sati
Radite li backup podataka?Novosti
Kako gledati sve utrke Formule 1 uz pomoć VPN-a?

Ako ste kao i mi, veliki ljubitelji motosporta i poglavito Formule 1 tada znate da u Hrvatskoj nije moguće pratiti ovaj sport uživo. Ipak, uz pomoć VPN usloga je moguće pratiti sve treninge, kvalifikacije, utrke kao i dodatan sadržaj na TV... Pročitaj više
Posljednji tjedan! Jeftini Microsoft Office Pro 2021 za 35,74 €. Nadogradite Windowse 11 Pro za samo 13,55 €!

Danas ćemo razgovarati o Officeu 2021 Pro i sigurnom načinu da dobijete Microsoftove ključeve po sniženoj cijeni! Office 2021, predstavljen u listopadu 2021., unapređuje nasljeđe svog prethodnika s poboljšanim značajkama kao što su suradnja... Pročitaj više
Riot Games navodno snima igranu seriju u Vijetnamu

(izvor slika) Na temelju uspjeha serije Arcane na Netflixu, Riot Games navodno razmatra igranu seriju kao svoj idući projekt. Navodno su vrlo blizu finaliziranja lokacija za snimanje koje će oživjeti jednu od ikoničnih regija iz igre. Prema... Pročitaj više
Nova RuneScape igra će uskoro izaći u rani pristup

RuneScape: Dragonwilds upravo je otkriven, donoseći nam još jednu igru serije RuneScape. Za razliku od glavne MMO igre, ovo će biti open-world survival igra, koja dijeli isto okruženje. RuneScape: Dragonwilds također je razvijen od strane J... Pročitaj više
Sonyjev novi model Xperia 1 VII oživljava 4K zaslon

Sonyjev vodeći telefon, Xperia 1 VI, prošle je godine napustio 4K zaslon, zbog čega su se mnogi "obožavatelji" sažalili. Međutim, najnovija curenja ukazuju na to da se očekuje da će se sljedeća generacija Xperije 1 VII vratiti na 4K ekrane.... Pročitaj više
Sve novosti