Nvidia GeForce GTX480 – brza i vruća
Datum objave 30.03.2010 - Krešimir Matanović
GF100 arhitektura
Pred vama je Nvidijin najnoviji GPU kodnog naziva GF100. Promjena
je to u odnosu na dosadašnju nomenklaturu, na koju se eto opet moramo privikavati.
GF100 je čip zasnovan na Fermi arhitekturi, koja implementira hardversku DirectX
11 podršku što uključuje teselaciju i DirectCompute. U odnosu na prethodnu
arhitekturu poboljšana je i "compute" arhitektura koja podržava
efekte kao što su raytracing, OIT (order-independent transparency) i simulacije
fluida. Treći je to Nvidijin GPU Computing proizvod, nakon G80 i GT200.
Ovaj se mega čip baš kao i AMD-ovi Cypressi proizvodi u Tajvanskom
TSMC-u u 40nm prizvodnom procesu. TSMC je kao što znamo imao probleme sa yieldom
zbog čega je AMD imao problema sa isporukom dovoljne količine kartica na tržište,
a to se je svakako odrazilo i na proizvodnju GF100 čipa. S jedne strane imate
tvornicu sa problemima u proizvodnji, a sa druge golemi čip od 3 milijarde
tranzistora koji ta ista tvornica treba proizvesti. Problemi i kašnjenja su
neminovni. No, nije tu TSMC jedini krivac, svakako im je lakše bilo proizvesti
Cypress koji ima 2.15 milijarde, nego ovaj, gotovo 50% veći. Nvidija je jednostavno
željela previše. GF100 u tih svojih 3 milijarde tranzistora i na preko 500
mm2 površine broji čak 480 stream procesora što je duplo više nego
na prethodnom GT200 čipu. Teksturnih i filter jedinica ima svakih po 60 (smanjenje
od po 20 u odnosu na GT200), a render back-endova je 48 što je za 16 više
nego na GT200. Oni koji prate razvoj Fermi arhitekture sjetiti će se kako
puni Fermi ima 512 stream procesora, odnosno 4x16x32 strukturu. Vjerojatno
zbog problema u proizvodnji taj je broj za GTX480 smanjen, ali nije isključeno
da se u budućnosti takav čip ne pojavi u jačem izdanju kartice (GTX490?).
GPU ima ukupno šest 64-bitnih memorijskih particija, što znači kako je sučelje
384-bitno. Podržano je maksimalno 6 GB GDDR memorije.

GF100 je baziran na skalabilnoj mreži klastera za procesiranje
grafike (u daljnjem tekstu GPC ili Graphics Processing Clusters), Streaming
Multiprocessor arhitekturi i memorijskim kontrolerima. Jedan GF100 se sastoji
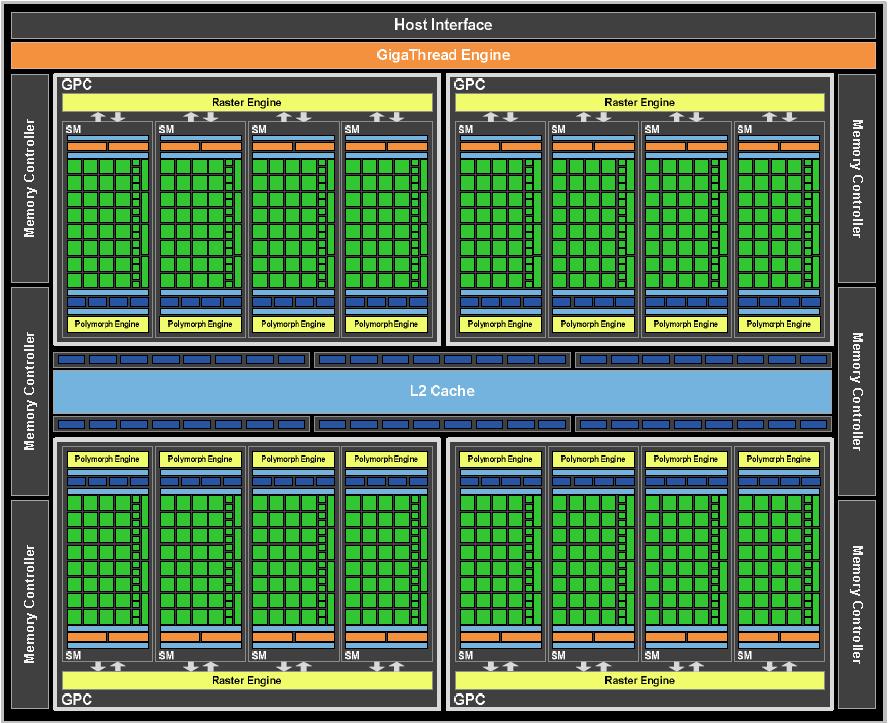
od četiri GPC-a, petnaest SM-a i šest memorijskih kontrolera. Na gornoj slici
tj. blok dijagramu GF100 čipa se vidi sučelje, GigaThread Engine, četiri GPC-a,
šest memorijskih kontrolera, šest ROP odjeljaka i 768 KB L2 cache memorije.
Svaki GPC ima četiri PolyMorph mehanizma. ROP odjeljci su smješteni tik do
L2 memorije. Čitava stvar funkcionira tako da GPU naredbe dobivene iz CPU-a
čita direktno preko sučelja, a GigaThread Engine dohvaća specifične podatke
iz sistemske memorije te ih kopira u video memoriju. Za brzi pristup video
memoriji tu su šest 64-bitnih GDDR5 memorijskih kontrolera. GigaThread mehanizam
nakon toga kreira i šalje nitne blokove u razne SM-e. Pojedini SM-i raspoređuju
ih u grupe od po 32 niti (warp) u CUDA jezgre i ostale izvršne jedinice. GigaThread
mehanizam također preraspodjeljuje posao u SM-e kada je dogodi ekspanzija
posla u grafičkom cjevovodu, što se dešava nakon faza teselacije i rasterizacije.
GF100 kao što smo napisali ima 480 CUDA jezgri, organiziranih kao 15 SM-ova
sa po 32 jezgre u svakom SM-u. Svaki SM je visoko paralelizirani mikroprocesor
koji je u stanju obraditi do 48 warpova (1536 niti) u svakom trenutku. CUDA
jezgra je unificirani procesor koji izvršava vertexe, pixele
i izračunava kernele. Unificirana L2 arhitektura priručne memorije
brine se o punjenju, spremanju i operacijama sa teksturama. GF100 ima 48 ROP
jedinica za pixel blending, antialiasing i atomske memorijske operacije (prikaz
višestrukih operacija kao jedne). ROP jedinice su organizirane u šest grupa
od po osam jedinica. Za svaku grupu je zadužen jedan 64-bitni memorijski kontroler.
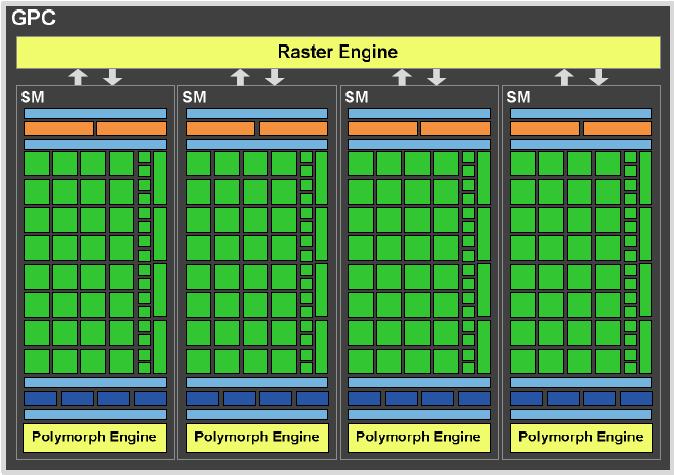
Pojedini GPC, kao dominantni high-end hardverski blok, se sastoji
od raster mehanizma i do četiri SM-a. Glavne odlike su mu skalabilni raster
mehanizam za podešavanje trokuta, rasterizaciju i Z-cull te skalabilni PolyMorph
mehanizam za dohvat vertex značajki i teselaciju. Raster mehanizam se nalazi unutar GPC-a, a PolyMorph mehanizam unutar SM-a.
Unutar GPC-a su sve ključne izršne jedinice za grafiku, tj. sve potrebno za
procesiranje verteksa, geometrije, rastera, tekstura i piksela. Uz iznimku
ROP funkcija, na GPC se može gledati kao na samo održivi GPU. GF100 kao što
znamo ima četiri takva GPC-a. Novost u odnosu na prethodne arhitekture je
i činjenica da SM ima četiri dedicirane teksturne jedinice, čime je eliminirana
potreba za TPC-ima (Texture Procesing Cluster) koji su postojali u G80 i GT200
arhitekturi. Svaki od 16 PolyMorph mehanizama ima svoju dediciranu verteks
dohvatnu jedinicu i teselator, štp povećava geometrijske performanse. Četriri
paralelna Raster mehanizma dozvoljavaju postaljanje do četiri trokuta po taktu,
što u suradnji sa PolyMorph mehanizmom znatno povećava performanse dohavta
trokuta, teselacije i rasterizacije. PolyMorph mehanizam ima pet stanja –
dohvat verteksa, teselacija, Viewport transformaciju (2-D trokut u kojeg se
projicira trodimenzionalna scena), postavljanje atributa te Stream Output
(izlaz verteksa prema memorijskom međuspremniku). Rezultati izračuna svake
pojedine faze šalju se u SM, gdje se izvršavaju shaderi, te se rezultati
ponovno vraćaju u nardenu fazu PolyMorph mehanizma. Nakon što su izvršene
sve faze, rezultati se proslijeđuju u Raster mehanizam. GPC predstavlja napredak
u arhitekturi cjevovoda geometrije jer teselacija zahtjeva veće performanse
trokuta i rasterizacije. Kako bi jednostavnije shvatili dovoljno je napomenuti
kako je uz uporebu dediciranog teselatora za svaki SM i Raster mehanizma za
svaki GPC, GF100 čip čak osam puta brži od GT200 kada su u pitanju performanse
geometrije.
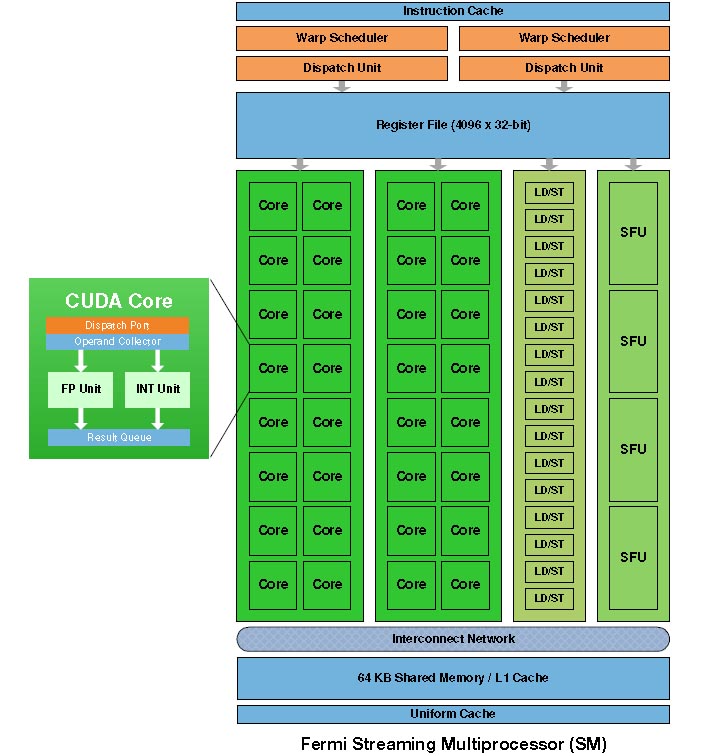
Svaki se SM, kao što smo već spomenuli sastoji od 32 CUDA procesora.
Svaki od procesora ima ALU i FPU jedinice sa punim cjevovodima. Prijašnji
su GPU-i koristili IEEE 754-1985 floating point aritmetiku, dok Fermi arhitektura
donosi novi IEEE 754-2008 floating-point standard, koji donosi FMA instrukcija
(fused multiply-add) kako za single tako i za double precision izračune, čime
se znatno povećava preciznost izračuna. U GT200, cjelobrojni ALU je bio ograničen
na 24-bitnu preciznost za operacije množenja, dok je u Fermiju cjelobrojni
ALU 32-bitni, a optimiziran je i za 64-bitne operacije. Svaki SM ima 16 load/store
jedinica, čime se adrese izvora i odredišta računaju u 16 niti po taktu. Jedinice
za podršku podatke uzimaju ili spremaju u priručnu memoriju ili DRAM. SFU
ili jedinice specijalne funkcije izvršavaju transcendetalne instrukcije, ali
i instrukcija grafičke interpolacije. Njihova brzina je jedna instrukcija
po niti po taktu. Warp Schedulera su ukupno dva po SM-u, a njihov je zadatak
paraleliziranje niti u grupe od po 32 (warpove) i slanje po jedne
instrukcije iz svakog warpa u grupu od šesnaest jezgri, šesnaest
load/store jedinica ili četiri SFU-a. Ugradnjom teksturnih jedinica u SM,
povećanjem efikasnosti priručne mamorije i povećanjem takta jedinica postigle
su se znatno veće performanse (četiri teksture po taktu). Teksturnih jedinica
po SM-u ima četiri a podržano je bilinearno, trilinearno i anisotropic filtriranje.
Redizajnom L1 arhitekture priručne memorije tekstura (svaki SM ima 64 KB on-chip
memorije koja se može konfigurirati kao 48 KB dijeljene memorije sa 16 KB
L1 cache memorije, ili 16 KB dijeljene memorije sa 48 KB L1 cache memorije,
ovisno da li izvršava CUDA ili grafičke aplikacije), i korištenjem L2 memorije
postignut je tri puta veći kapacitet nego na prethodnoj, GT200 arhitekturi.
GF100 ima ukupno 768 KB unificirane L2 cache memorije koja je
zadužena za sve zahtjeve o punjenju, spremanju i operacijama sa teksturama.
Hardverska arhitektura priručne memorije posebno pogoduje algoritmima za koje
nisu prethodno poznate adrese (fizika, ray tracing, raštrkani podaci). Post
processing filteri koji zahtjevaju da višestruki SM-i čitaju iste podatke
sada trebaju manje "posjeta" memoriji što u konačnici povećava propusnost.
Prednost unificirane cache arhitekture je u njenom boljem iskorištenju, a
L2 arhitektura na GF100 zamjenjuje teksturni cache, ROP cache i on-chip FIFO
(first-in first-out).
ROP podsistem je redizajniran, pa tako jedna ROP particija sadrži
osam ROP jedinica. Svaka ROP jedinica može izbaciti 32-bitni integer piksel
po taktu, tj. FP16 piksel za dva odnosno FP32 piksel za četiri takta. Kada
je kvaliteta prikaza slike u pitanju, zbog navedenog ima pomaka na bolje.
8xMSAA performanse su se po Nvidijinim riječima znatno poboljšale zbog veće
efikasnosti kompresije te dodatnih ROP jedinica. Tu je novi 32xCSAA (Coverage
Sampling Antialiasing) mod koji je baziran an osam višestrukih i 24 pokrivna
uzorka. CSAA sada podržava i alpha-to-coverage (transparency multisampling)
na svim uzorcima, što se odrazilo renderiranju lišća i prozirnih tekstura,
učinivši ih glađim. GF100 postiže jednaku AA kvalitetu kako za rubove poligona,
tako i za alfa teksture uz minimalni gubitak performansi. Performanse mapiranja
sjena su se također podigle, sa hardverski ubrzanim DirectX 11 four-offsetom
Gather4.
Nvidijina 3D Vision tehnologija je pristuna i kod ove nove arhitekture,
a novost je 3D Vision Surround. Ona omugućava 3D sliku rastegnutu preko tri
monitora maksimalne rezolucije 5760×1080 za što će vam biti potrebne dvije
GTX400 ili dvije GTX200 kartice u SLI konfiguraciji, tri 3D Vision capable
monitora te Nvidijine 3D naočale. Za one koji ne žele igru u 3D okruženju,
NVIDIA Surround će omogućavati igru u maksimalno 2560 x 1600 preko monitora
koji dijele istu rezoluciju. Nvidija će pripremiti i Bezel Correction NVIDIA
3D Vision Surround koji će kompenzirati razmake nastale zbog okvira monitora.
Surround je dakle tehnološki daleko od konkurentskog Eyefinitya, te je jedina
prava prednost 3D igranje (za one koji ga vole i podnose).
Forum
Objavljeno prije 14 minuta
AutomobiliObjavljeno prije 19 minuta
Privatnost i sigurnost podataka i korisnikaObjavljeno prije 29 minuta
Mozilla FirefoxObjavljeno prije 37 minuta
HT - MAX 5G InternetObjavljeno prije 55 minuta
2x Dell AS501 SoundBar (zvucnici) za LCD, Original Maske za iPhone XS Max, 12 Pro MaxNovosti
Elden Ring Nightreign dodaje novu klasu

Elden Ring Nightreign otkriva novu klasu pod nazivom Ironeye, koja nudi preuređeni pristup igranju na daljinu. Iako je Elden Ring Nightreign odvojen od osnovnog naslova Elden Ring, neke od promjena u stilovima igre u ovom spin-offu ostavile... Pročitaj više
FromSoftware najavljuje The Duskbloods

FromSoftware će kasnije ove godine izdati Elden Ring: Nightreign, ali ne znamo mnogo o planovima developera za budućnost. Do danas nije bilo novih igara na vidiku, a Nightreign djeluje više kao spinoff naslov koji povezuje sadašnje vrijeme... Pročitaj više
Potencijalno izlaze još dvije Assassin’ s Creed igre u 2025.

(izvor slike) Assassin's Creed Shadows tek je izašao, ali Ubisoft bi već mogao imati još jednu igru u pripremi. Prema Tomu Hendersonu, glavnom uredniku Insider Gaminga, Codename Invictus "trebao bi" biti lansiran kasnije ove godine. Nije ri... Pročitaj više
Zašto 4G/5G veza troši više baterije vašeg pametnog telefona?

Jeste li ikada primijetili da se baterija vašeg telefona brže prazni kada koristite mobilne podatke nego kada ste spojeni na WiFi mrežu? Postoji li korelacija između pražnjenja baterije i internetske veze putem mobilnih podataka u odnosu na... Pročitaj više
Kako gledati sve utrke Formule 1 uz pomoć VPN-a?

Ako ste kao i mi, veliki ljubitelji motosporta i poglavito Formule 1 tada znate da u Hrvatskoj nije moguće pratiti ovaj sport uživo. Ipak, uz pomoć VPN usloga je moguće pratiti sve treninge, kvalifikacije, utrke kao i dodatan sadržaj na TV... Pročitaj više
Sve novosti