Novi trendovi u umjetnoj inteligenciji: AI modeli bez podatkovnih centara?

Umjetna inteligencija postaje sve moćnija, ali iza kulisa njezina razvoja kriju se ogromni resursi – doslovno. Trenutno najnapredniji AI modeli poput ChatGPT-a, Claudea i Geminija treniraju se na nevjerojatnim količinama podataka, u podatkovnim centrima krcatim GPU-ovima, gdje svaka sekunda košta bogatstvo. Sve to znači da najjači modeli dolaze isključivo iz najvećih i najbogatijih kompanija. Ali što ako vam kažemo da postoji novi pristup – jedan koji ne treba superračunala ni klimatizirane hale prepune servera?
Flower AI i Vana mijenjaju pravila igre
Dvije tvrtke – Flower AI i Vana – odlučile su okrenuti sve naopačke i dokazati da se može i drugačije. Udružili su snage i izgradili novi AI model pod nazivom Collective-1 koristeći… obične kompjutere spojene preko interneta. Da, dobro ste pročitali. Bez centralizirane infrastrukture. Bez podatkovnih centara.
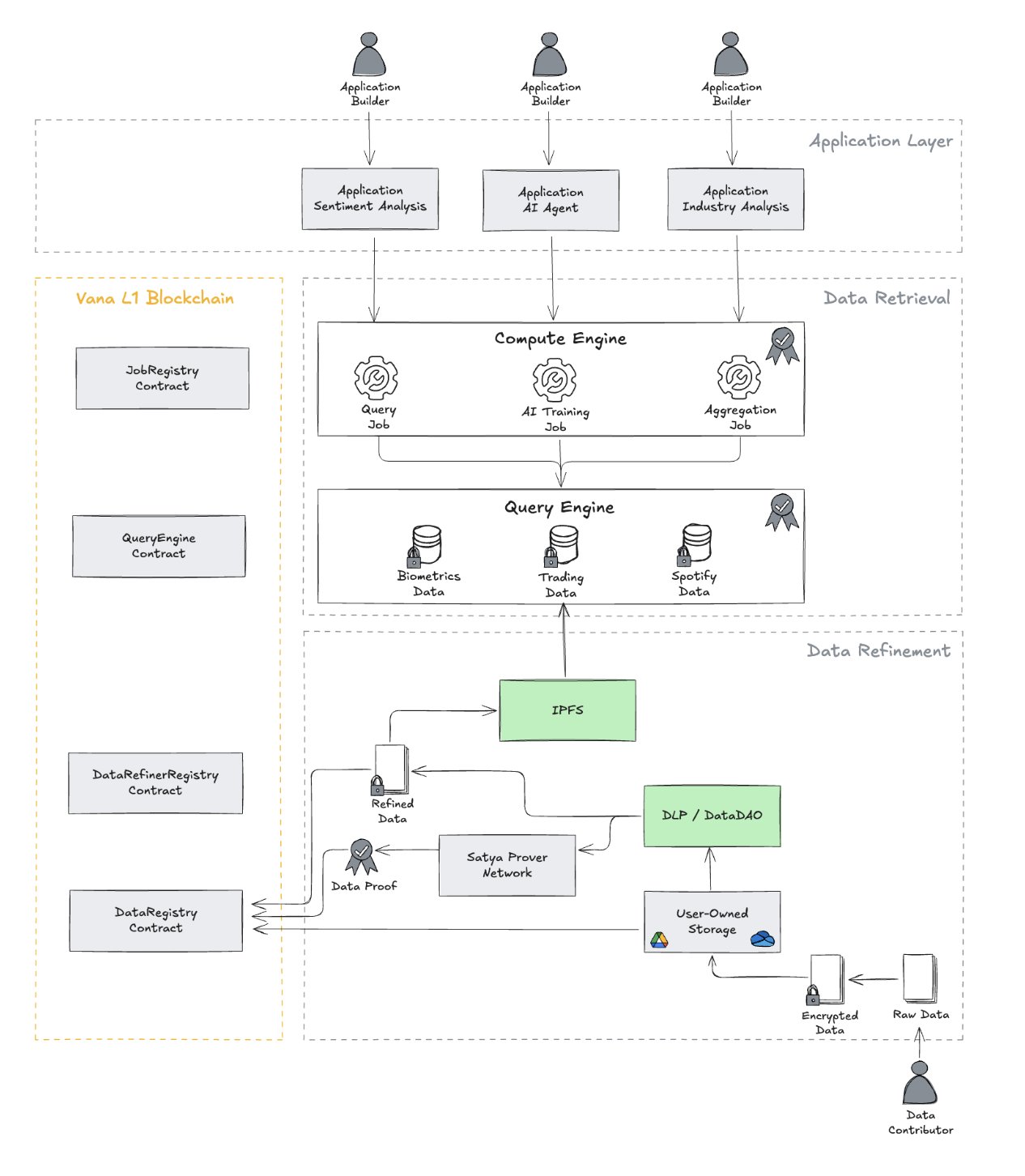
Flower AI je razvio tehnologiju koja omogućava distribuciju procesa učenja na stotine (pa i tisuće) računala raštrkanih diljem svijeta. Vana je pak doprinijela podacima – uključujući privatne poruke korisnika s platformi poput X-a, Reddita i Telegrama – naravno, uz pristanak korisnika. Štoviše, korisnici čak mogu imati kontrolu nad tim kako se njihovi podaci koriste i potencijalno ostvariti financijsku korist.
Što je Collective-1 i zašto je važan?
Collective-1 ima 7 milijardi parametara – što nije ni blizu ChatGPT-ovih stotina milijardi, ali koncept iza njega je ono što stvarno nosi potencijal za revoluciju. Bit je u tome da nije treniran u nekom velikom centru, već na distribuiran način – na hardveru koji se može nalaziti bilo gdje, povezan standardnim (često i nestabilnim) internetskim vezama. I to nije sve – Nic Lane, računalni znanstvenik s Cambridgea i suosnivač Flower AI-ja, kaže da već treniraju model sa 30 milijardi parametara, a do kraja godine planiraju i jedan s 100 milijardi – što je razina današnjih top modela. I sve to bez podatkovnog centra!
Photon – alat koji omogućava sve to
Za ovaj pothvat razvijen je novi open-source alat pod nazivom Photon, u suradnji s kineskim sveučilištima. Photon optimizira kako se podaci dijele i spajaju tijekom procesa treniranja modela. U praksi, to znači da obuka ide sporije nego u tradicionalnim uvjetima, ali se zato može fleksibilno širiti – dodaj još jedno računalo i model trenira brže.
Što sve to znači za budućnost AI-ja?
Ovakav pristup mogao bi doslovno demokratizirati razvoj umjetne inteligencije. Dosad su vrhunski modeli bili privilegij samo tehnoloških divova s pristupom rijetkim i skupim GPU-ovima. No s distribuiranom metodom, čak i manji startupi, sveučilišta ili zemlje bez skupe infrastrukture mogu početi razvijati konkurentne modele. Mirco Musolesi s University College London vjeruje da je ovo posebno važno za industrije poput zdravstva i financija, gdje se radi o vrlo osjetljivim podacima. Distribuirani pristup omogućuje obradu tih podataka lokalno, bez potrebe za slanjem u centralizirane sustave – što je ogroman plus za privatnost i sigurnost.
Nove mogućnosti za korisnike – i nova pitanja
Partnerstvo s Vanom otvara još jednu veliku temu – vlasništvo nad podacima. Njihov softver omogućuje korisnicima da sami odlučuju žele li dijeliti svoje privatne podatke za treniranje AI-ja, te pod kojim uvjetima. Osim toga, korisnici potencijalno mogu ostvariti prihod ako se njihovi podaci iskoriste. Dakle, prvi put korisnici ne samo da mogu doprinositi razvoju AI-ja, već i imati konkretne koristi od toga.
Zaključak: Početak nečeg novog?
Iako je Collective-1 još uvijek mali u usporedbi s divovima, ideja koja stoji iza njega je ogromna. Ako ovakav pristup zaživi – a sve više stručnjaka vjeruje da hoće – mogli bismo gledati potpuni zaokret u razvoju umjetne inteligencije. Umjesto centraliziranih giganata, mogli bismo imati mreže decentraliziranih, suradničkih sustava u kojima i obični korisnici sudjeluju, doprinose – pa čak i imaju udjela u rezultatima. Ovo bi mogao biti početak jedne sasvim nove AI ere – tiše, fleksibilnije i daleko pravednije.