TPU vs. GPU: Što stvarno razlikuje Googleov pristup umjetnoj inteligenciji od ostatka industrije?

Razvoj umjetne inteligencije ušao je u fazu u kojoj performanse hardvera određuju brzinu inovacija. Gigantske AI modele poput Gemini, GPT ili Llama više ne mogu pogoniti standardna računala – za to su potrebni specijalizirani čipovi. Danas dominiraju dvije vrste akceleratora: GPU čipovi, koje razvijaju tvrtke poput NVIDIE i AMD-a, te TPU čipovi (Tensor Processing Unit), koje je razvio Google.
Iako se na prvi pogled čine sličnima – oba ubrzavaju AI izračune – iza njih stoje potpuno različite filozofije dizajna, ekosustavi i namjene. Ovaj članak objašnjava ključne razlike, njihovu ekonomiku i zašto Google TPU-e može koristiti na način koji drugi jednostavno ne mogu.
1. Filozofija dizajna: TPU kao specijalist, GPU kao generalist
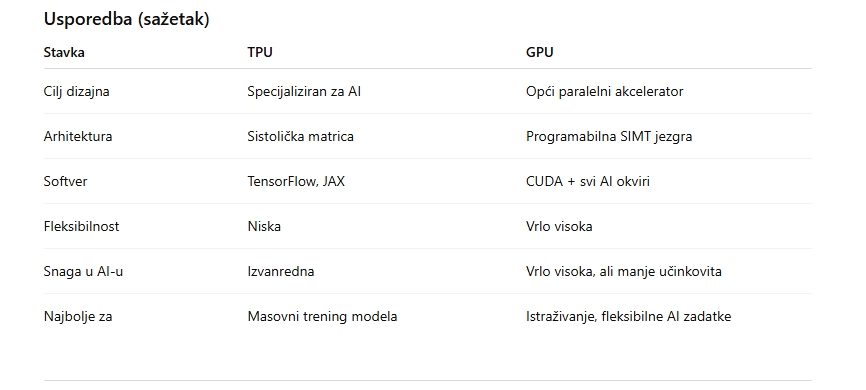
Najvažnija razlika između TPU-a i GPU-a leži u tome za što su izvorno dizajnirani.
TPU specijalist za AI – Google je razvio TPU isključivo za jedan zadatak: matrično računarstvo, koje je temelj dubokog učenja. Većina neuronskih mreža svodi se na masivne, ponavljajuće operacije matrica poput GEMM (General Matrix Multiplication). TPU-ovi koriste sistoličku arhitekturu niza – podatci se u “valovima” kreću kroz mrežu računskih jedinica, minimizirajući komunikaciju s memorijom (najskuplji dio obrade). To daje ogromnu energetsku učinkovitost i propusnost.
Zaključak: TPU je poput F1 bolida – nevjerojatno brz u jednom segmentu.
GPU fleksibilni generalist – GPU čipovi razvijeni su za grafiku, a kasnije su se “prirodno” pokazali idealnima za paralelno računanje. NVIDIA-ine SIMT arhitekture imaju tisuće programabilnih jezgri i izuzetnu fleksibilnost, što GPU čini pogodnim ne samo za AI, nego i za renderiranje 3D grafike, fizikalne simulacije, emulaciju i gaming, znanstvena istraživanja, kriptovalute i opće HPC računarstvo.
Zaključak: GPU je poput švicarskog noža – može poslužiti u gotovo svakoj situaciji.
Usporedba (sažetak)
2. Performanse i troškovi: Zašto Google gura Ironwood i TPU klastere
Googleova najnovija TPU platforma Ironwood postavlja nove standarde u sustavima za obuku velikih modela .Ključne prednosti TPU-a u praksi:
- Ogromna skalabilnost – preko 9.000 čipova u jednoj konfiguraciji
- 40+ PFLOPS računske snage na razini klastera
- 2–3× bolji omjer performansi po vatu u odnosu na GPU
- Znatno niži troškovi po modelu na dugoročnom treningu
Google je izračunao da kompletan zadatak zaključivanja (inference) velikog modela može koštati od 45,6 mil. USD 172 mil. USD, ali ušteda od preko 70% – na razini čitavog podatkovnog centra to znači stotine milijuna USD razlike. U svijetu u kojem AI modeli rastu iz tjedna u tjedan, takva ušteda postaje strateška prednost.
3. Ako su TPU-i bolji, zašto GPU-i još dominiraju?
Ovo je najčešće pitanje. Odgovor ima tri ključna razloga:
A. Softverski ekosustav (CUDA je kralj) – Istraživači, startupi i tvrtke već desetljećima razvijaju na NVIDIA CUDA platformi. Sve radi odmah – PyTorch, TensorFlow, Hugging Face, JAX, Numba…
Prebacivanje cijele industrije s CUDA-e na TPU arhitekturu bio bi skup, rizičan i disruptivan. Google taj rizik može tolerirati jer je jedini korisnik vlastitih TPU-a. Drugi – ne.
B. TPU nije općenito računalstvo – TPU je briljantan u matričnim izračunima, ali simulacije, grafika, fizika, znanstveni proračuni i dinamički algoritmi rade sporije ili uopće ne rade na TPU-ima. GPU može pokriti sve te domene – i zato je univerzalni standard.
C. TPU-i nisu roba – GPU-i jesu jer ih može kupiti svatko, mogu se staviti u vlastiti server ili gaming PC i mogu raditi offline.
TPU:
✘ većinom dostupan samo preko Google Clouda
✘ nije fizički hardver koji tvrtka može kupiti
✘ teško se integrira u postojeću infrastrukturu
→ Za 99% tvrtki GPU je jedina racionalna opcija.
4. Zašto Google može trenirati velike modele na TPU-ima, a drugi ne
Google je jedini igrač koji može postići masovni trening na TPU-ima jer posjeduje potpunu vertikalnu integraciju:
Google kontrolira: hardver (TPU), kompajlere i softver (XLA, JAX, TensorFlow), modelne arhitekture (Gemini), podatkovne centre. operativni sustav i infrastrukturu. To znači da Google može optimizirati cijeli AI lanac iznutra, što je nemoguće replicirati. Meta, OpenAI, Amazon i drugi koriste GPU-e jer ne kontroliraju cijeli ekosustav i jer bi ASIC pristup predstavljao ogroman rizik: Ako se algoritmi promijene, specijalizirani TPU čip postaje zastario , a GPU jednostavno preuzima novi radni zadatak.
5. Perspektiva za Hong Kong: dvoslojna AI arhitektura
Sve više istraživačkih institucija testira Google Cloud TPU klastere. Buduća infrastruktura vjerojatno će slijediti globalni trend:
- Dvotračna struktura tržišta
- TPU za masovne AI zadatke (trening LLM modela, veliki batch inference)
- GPU za sve ostalo (istraživanje, vizualizacija, fizika, AI prototipiranje, opći HPC)
Takva podjela omogućuje optimalan odnos cijene i performansi, koji je ključan za lokalne tvrtke i istraživačke projekte.
Zaključak: TPU i GPU nisu konkurenti – nego partneri u AI ekosustavu
TPU-ovi su neupitno brži i jeftiniji za masovne AI operacije. GPU-i su nezamjenjivi u fleksibilnosti, razvoju i općem računalstvu.
Industrija se zato kreće prema koegzistenciji, a ne prema zamjeni.
- TPU → za specijalizirane AI divove poput Googlea
- GPU → za sve koji trebaju univerzalnost i kompatibilnost



